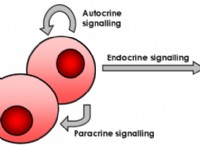
遺伝子クラスタリング:要約
Gene Clusteringは、バイオインフォマティクスで使用される手法であり、その類似性に基づいて遺伝子をグループ化します。これには、遺伝子発現データ、タンパク質配列、またはその他の遺伝情報のデータセットを分析して、同様のパターンまたは特性を示す遺伝子のグループを特定します。
ここに重要な側面の内訳があります:
1。目的:
* 機能的関係を識別する: 結束する遺伝子は、多くの場合、同様の生物学的プロセスまたは経路に関与しています。
* 新規遺伝子を発見: クラスタリングは、既知の遺伝子との関連に基づいて、不明な機能を持つ遺伝子を特定するのに役立ちます。
* データの複雑さを削減: 類似性に基づいた遺伝子のグループ化は、大きなデータセットの分析を簡素化します。
* 遺伝子調節を理解: クラスタリングは、さまざまな刺激や条件に応じて遺伝子がどのように調節されるかを明らかにすることができます。
2。方法:
* 階層クラスタリング: 類似の遺伝子が連続したレベルでグループ化される木のような構造を作成します。
* k-meansクラスタリング: クラスター重心からの距離に基づいて、遺伝子を固定数のクラスターに割り当てます。
* 自己組織化マップ(SOM): ニューラルネットワークを使用して、高次元データを低次元グリッドにマッピングし、データ内のクラスターを明らかにします。
3。使用されるデータ:
* 遺伝子発現データ: さまざまな条件下で遺伝子活性のレベルを測定します。
* タンパク質配列: タンパク質の構造と機能の類似性を識別します。
* 遺伝子調節ネットワーク: 遺伝子とそれらの調節要素間の相互作用を研究します。
4。アプリケーション:
* 創薬: 特定の疾患に関与する遺伝子を見つけることにより、潜在的な薬物標的を特定します。
* 疾患診断: 遺伝子発現パターンに基づいて、異なる疾患サブタイプを分類します。
* 個別化医療: 遺伝的プロファイルに基づいた個々の患者へのテーラー治療。
* 進化生物学: 遺伝子とそれらの進化的起源との関係を研究します。
5。制限:
* クラスタリング方法の選択: さまざまな方法で異なる結果が生じる可能性があります。
* データ品質: データのノイズとバイアスは、クラスタリングの結果に影響を与える可能性があります。
* クラスターの解釈: クラスターの生物学的意義を決定するには、さらなる分析が必要です。
本質的に、Gene Clusteringは、複雑な遺伝データを調査し、パターンを特定し、生物系内の遺伝子の組織と機能に関する洞察を得るための強力なツールです。