RNA は、転写と呼ばれるプロセスで DNA から生成されます。転写は、DNA テンプレートを読み取り、RNA 鎖に相補的なヌクレオチドを追加する RNA ポリメラーゼによって実行されます。転写のプロセスでは、1 つのテンプレートに複数のポリメラーゼが存在する可能性があり、転写は複数のラウンドで発生する可能性があります。
DNAは生命の設計図です。それは、私たちのすべての細胞が機能するための情報です。細胞とその機能について読むと、タンパク質や酵素(触媒として機能するタンパク質)などの用語に出くわしますが、細胞がどのタンパク質を作るべきかをどのように知っているのか疑問に思ったことはありませんか?または、実際のタンパク質の正確な構造は何ですか?これは、私たちの DNA によって行われる仕事です。それは基本的に、すべてのタンパク質のアミノ酸の配列をヌクレオチド配列の形で保持する記憶単位として機能します(アミノ酸はタンパク質を構成する基本単位であり、その配列はそれがどのタンパク質であるかを決定します!). DNAの構造と方向性をカバーしているため、DNA複製に関する記事を読んでおくと、プロセスをよりよく理解できます.ここで読んでみてください!
では、私たちの DNA はこの配列についてどのように細胞に伝えると思いますか?メッセージを送ることで!いいえ、SMS や Whatsapp テキストではなく、ヌクレオチド形式のメッセージです。これらのヌクレオチドの配列は各タンパク質に固有ですが、これらのヌクレオチドは DNA ではなく、RNA を使用してこれを行います。また、DNA とは異なり、この RNA 配列は一本鎖です。私たちの創造力のおかげで、私たちはこの RNA を mRNA、つまりメッセンジャー RNA と名付けました。
DNA から mRNA 配列を生成するプロセスは、転写として知られています。それでは、これがどのように起こるかを見てみましょう!
DNA 転写
DNA が二本鎖であることはわかっていますが、コード鎖 (センス鎖とも呼ばれます) として知られている鎖は 1 本だけです。したがって、mRNA の配列はコード鎖と類似しているはずです。どうすればそれを達成できますか?相補的な非コード鎖 (アンチセンス鎖とも呼ばれます) をテンプレートとして使用することにより!これはとても重要なことなので、頭の片隅に置いておいてください。コード鎖はテンプレートとして使用されません。それでは、プロセスを順を追って見ていきましょう。
開始
RNA シーケンスを作成するプロセスは、転写因子の助けを借りて、RNA ポリメラーゼによって実行されます。転写因子は、RNAポリメラーゼがプロモーター配列と呼ばれる配列を認識して結合するのを助けます。ポリメラーゼは、DNA の約 14 塩基対を巻き戻し、RNA ポリメラーゼ プロモーターの開いた複合体を形成します。この一本鎖の DNA は「転写バブル」として知られています。
ポリメラーゼがその仕事を続け、ヌクレオチドを追加して mRNA を作るためには、プロモーターから切り離す必要があります。これは、中絶開始と呼ばれるプロセスを通じて発生します。このプロセス中に、ポリメラーゼは短い mRNA 転写産物を作成します。これは、ポリメラーゼがプロモーターから切り離される前に放出されます。
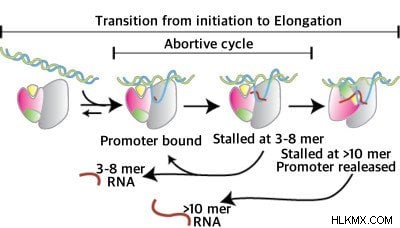
プロモーターエスケープ。 (写真提供:ルイス・E・ラミレス・タピア / ウィキメディア・コモンズ)
伸び
プロモーターから切り離しても、残ったポリメラーゼは動かないことが観察された。では、ポリメラーゼが動かずにどのようにテンプレートを読み取るのかという疑問が生じます。その答えが DNA シュシュです (シュシュとは、押しつぶす、または絞り出すことを意味します)。ポリメラーゼが静止している間、DNA テンプレートを転写複合体に引き込みます。テンプレートはポリメラーゼの活性部位を通過するため、移動を必要とせずに転写が行われます!巻き戻された DNA は複合体に蓄積するため、DNA シュシュと呼ばれます。その後、ポリメラーゼは巻き戻し、巻き戻された DNA の下流部分を解放します。
ポリメラーゼは、テンプレートに沿って移動します (テンプレートは 3' から 5' の方向に実行されます)。これは、RNA ポリメラーゼが mRNA を 5' から 3' の方向に作ることを意味します。テンプレートを読み取り、相補的なヌクレオチドを RNA 配列に追加します。このプロセスは、終了シーケンスに到達するまで続きます。
転写のプロセスでは、単一のテンプレートに複数のポリメラーゼが存在する可能性があり、転写は複数のラウンドで発生する可能性があります。これにより、単一のテンプレートから多数の mRNA を作成できます。伸長には校正メカニズムもあり、誤って挿入されたヌクレオチドを置換し、配列を正確に保つのに役立ちます!
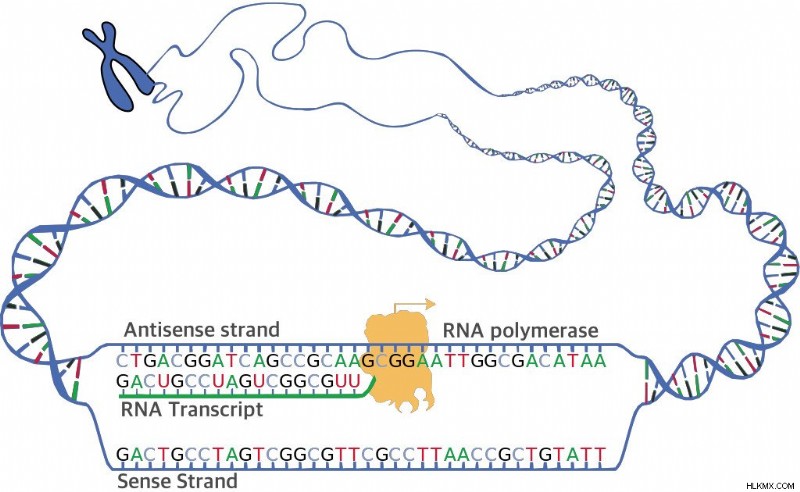
DNA転写。 (写真提供:国立ヒトゲノム研究所 / ウィキメディア・コモンズ)
終了
末端には2つのタイプがあり、1つ目はRho非依存性、2つ目はRho依存性です(Rho因子はタンパク質です)。 1 つずつ見ていきましょう。
- Rho非依存性転写終結 – このプロセスでは、ポリメラーゼはグアニンとシトシンの終結配列に到達します。これに続いて一連のアデニンが繰り返されます。次に、グアニン-シトシン領域にループが形成され、グアニンがシトシンと3つの水素結合を形成するため、RNAポリメラーゼがこれらを結合するのに時間がかかります.このすべてがアデニン領域に負担をかけ、鎖が切断され、ポリメラーゼが放出されます!
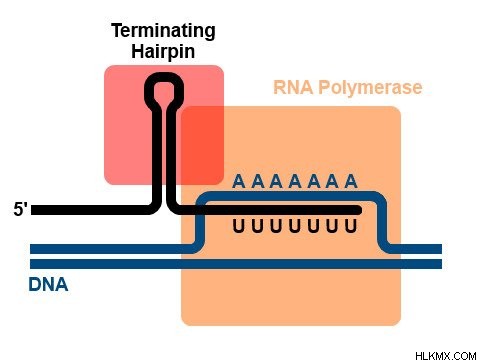
Rhoに依存しない終了。 (写真提供:Oalnafo1 / ウィキメディア・コモンズ)
- Rho 依存性転写終結 – Rho タンパク質は終結配列に到達するまで RNA 配列に沿って移動します。終結配列に到達すると、Rho タンパク質はテンプレートと RNA 配列間の相互作用を不安定にします。
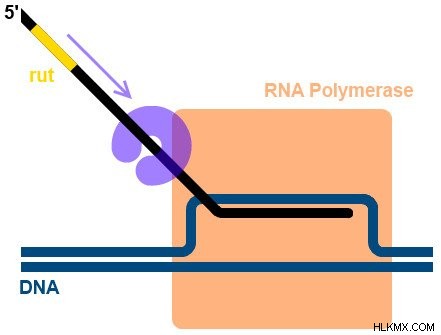
Rho 依存性転写終結。 (写真提供:Oalnafo1 / ウィキメディア・コモンズ)
真核生物と細菌
真核生物とバクテリアで転写が起こる方法にはいくつかの違いがあります.
<オール>