バイオインフォマティクスの簡単な歴史:DNAからデータサイエンスまで
生物学、コンピューターサイエンス、統計をブレンドする分野であるバイオインフォマティクスは、比較的最近の歴史を持っていますが、現代の生物学的研究に大きな影響を及ぼしています。主要なマイルストーンのタイムラインは次のとおりです。
初期(1960年代から1980年代):
* 1960年代: 「計算生物学」の概念が生まれ、生物学的プロセスの数学モデルに焦点を当てています。
* 1970年代: 「Protein Data Bank」(PDB)などのタンパク質配列データベースの開発は、生物学的データの保存と分析に向けた最初のステップを示しています。
* 1980年代: サンガーシーケンスのような最初のDNAシーケンス技術の開発は、利用可能な遺伝情報の劇的な増加につながります。
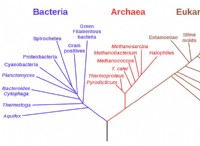
バイオインフォマティクスの誕生(1990年代):
* 1990: ヒトゲノムプロジェクト(HGP)が始まり、ヒトゲノム全体をマッピングすることを目指しています。この野心的なプロジェクトでは、データ分析とストレージのための洗練されたツールの開発が必要です。
* 1995: 自由生活生物の最初の完全なゲノムである *haemophilus influenzae *が配列決定されます。
* 1998: 最初の商用バイオインフォマティクス会社であるIncyte Genomicsが確立されています。
バイオインフォマティクスブーム(2000年代以前):
* 2000: ヒトゲノムの最初のドラフトが公開されており、バイオインフォマティクスの歴史の主要なマイルストーンをマークしています。
* 2003: HGPはヒトゲノムのシーケンスを完了し、ゲノム研究の急増と大規模なデータセットの利用可能性をもたらします。
* 2000年代以降: 次世代シーケンス(NGS)などのシーケンス技術の急速な進歩は、膨大な量の生物学的データを生成し、ますます洗練されたバイオインフォマティクスツールとアルゴリズムの開発を促進します。
* 2010S-Present: マイクロアレイ、RNAシーケンス、プロテオミクスを含むハイスループット技術の台頭により、バイオインフォマティクスの領域がさらに拡大します。
* 存在: バイオインフォマティクスは、創薬、個別化医療、病気の診断、環境モニタリングなど、さまざまなアプリケーションで重要な役割を果たしています。
重要な貢献者:
* マーガレット・デイホフ: タンパク質配列分析の先駆者と最初の包括的なタンパク質データベースの作成者。
* Walter Goad: タンパク質構造を分析するための最初のコンピュータープログラムを開発しました。
* デビッドリップマン: シーケンスアライメントアルゴリズムとバイオインフォマティクスデータベースの開発に大きく貢献しました。
* サミュエル・カーリン: バイオインフォマティクスにおける統計的手法の使用、シーケンス比較のためのアルゴリズムの開発と系統解析の先駆者となりました。
先を見据えて:
バイオインフォマティクスの分野は、人工知能(AI)、機械学習、クラウドコンピューティングの進歩によって駆動され、急速に進化し続けています。将来の開発は次のことに焦点を当てることが期待されています。
* ビッグデータ分析: 大規模な生物学的データセットの取り扱いと解釈。
* 予測モデリング: AIを使用して、疾患のリスク、薬物の有効性、および生物学的相互作用を予測します。
* 個別化医療: 個々の遺伝的プロファイルに基づいて医療治療を調整します。
バイオインフォマティクスは、生物系の理解と相互作用の方法を変えました。拡大し続けるリーチと影響により、21世紀の科学的発見の基礎となる可能性があります。